滑动轴承磨损表面与磨粒信息映射模型研究
发布时间:2014-11-04袁成清 王志芳 周志红 严新平
(武汉理工大学能源与动力工程学院,武汉 430063)
摘 要:针对磨损监测过程中获得的大量参数之间存在冗余及关联影响自动识别这一问题,首先运用粗糙集理论和主元分析2种不同的数据约简方法对监测数据进行约简,然后采用支持向量机建立滑动轴承磨粒信息和磨损表面信息之间的映射关系识别器。应用示例表明建立的模型对识别滑动轴承的磨损表面信息和磨粒信息映射关系具有较好的效果。(武汉理工大学能源与动力工程学院,武汉 430063)
关键词:滑动轴承;磨损;磨粒;粗糙集;主元分析;支持向量机
摩擦学系统的状态辨识已经成为获取摩擦学系统运行特征、开展摩擦学系统运行机理研究和面向全寿命周期的摩擦学系统设计的重要方法和手段[1,2]。磨损表面和磨粒信息是判别磨损状态的重要依据[1,2]。磨损表面和磨粒信息的描述参数已由二维发展到三维,现所能获得的参数有上百个[3],这在理论上来说是很大的提升,但是在实际应用方面并不是所有的参数都需要,因为这些参数之间存在着冗余;同时参数越多,在用数学方法建立磨损表面信息和磨粒信息映射关系时越困难。为了解决此问题,需要进行数据属性约简或数据降维。研究将粗糙集理论、主元分析方法以及近年来引起密切关注并且在分类、回归估计和密度估计等方面有较好应用的支持向量机联合,用于研究滑动轴承磨损表面信息和磨损过程中产生的磨粒信息之间的对应关系,找出适用于磨粒信息和磨损表面信息之间映射关系的模型,为摩擦学系统状态辨识提供新的解决思路。
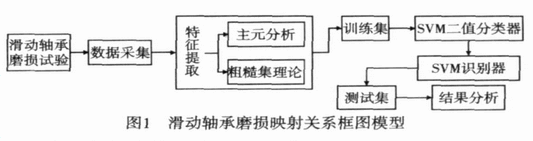
1 建立滑动轴承映射关系模型的基本原理
1)基本原理 粗糙集理论和主元分析都可用于属性约简,粗糙集理论[4]是利用不可分辨二元等价关系来消除冗余属性,得到的约简集合是具有代表性的具体属性;主元分析[5]用于属性约简的主要原理是数据空间降维,将原来的n维空间降至能表达原始数据的大部分信息的m维(m<n)。
首先将2种属性约简方法分别用于滑动轴承磨损试验数据的属性约简,然后利用支持向量机(support vector machine,简称SVM)[6,7]对约简后的试验数据进行训练和识别测试,比较其识别结果,找出适合于滑动轴承滑动磨损试验获得的磨粒信息和磨损表面信息之间的映射识别模型,其基本流程如图1所示。SVM是数据挖掘中的一个新方法,其实质是Z大边缘区分类器。由SVM的原理[6,7]可知,它在分类问题上只考虑了二值分类的问题,而滑动轴承磨损映射关系是多值分类问题,需要通过组合多个二值子分类器来实现,常用的构造方法有一对多(one versus rest,简称1-v-r)模式和一对一算法(one versus one,简称1-v-1)。研究中,采用前者一对多(1-v-r)模式。在这种模式下,每一类别和其他所有类别之间构造分类函数,对于k类滑动轴承磨损映射关系的分类问题,需要构造k个SVM分类器模型。对于第j(j∈[1,k])个子分类器模型,将属于第j类的磨损样本作为一类,标记为“1”,其余k-1类磨损样本作为另外一类,标记为“-1”。决策时,将待检测磨粒样本依次输入到各SVM子分类器模型中,计算各个子分类器的判别函数值,并选取判别函数值Z大所对应的类别为待检测磨损样本的类别。

2.1试验介绍
在MMW-1万能磨损试验机上开展销2盘形式的滑动轴承材料的滑动磨损试验。试验中选取的盘试样材料为40号调质钢;配对的销试样材料为锡基合金,其牌号为ZSnSb11Cu6。
在磨损试验机上模拟了滑动轴承材料磨损的4种典型磨损形式:正常磨损、擦伤、划伤和粘着磨损。在磨损过程中收集润滑油油样,通过磨粒分析,获得一系列磨粒的属性值数据,选取的属性有21个,分别为:面积、周长、主轴长度、主轴宽度、纤维长度、体态比、纤维比率、圆度、弯曲度、实心度、边界分形维数、宽度、矩形度、主轴/Z大宽度、平均亮度、表面算术平均粗糙度Ra、表面平均轮廓波峰高度Rp、表面分形维数、表面平均轮廓波谷深度Rv、表面轮廓总高度Rt、纤维长度/体态比。
2.2建立滑动轴承磨损表面和磨粒信息的映射关系模型
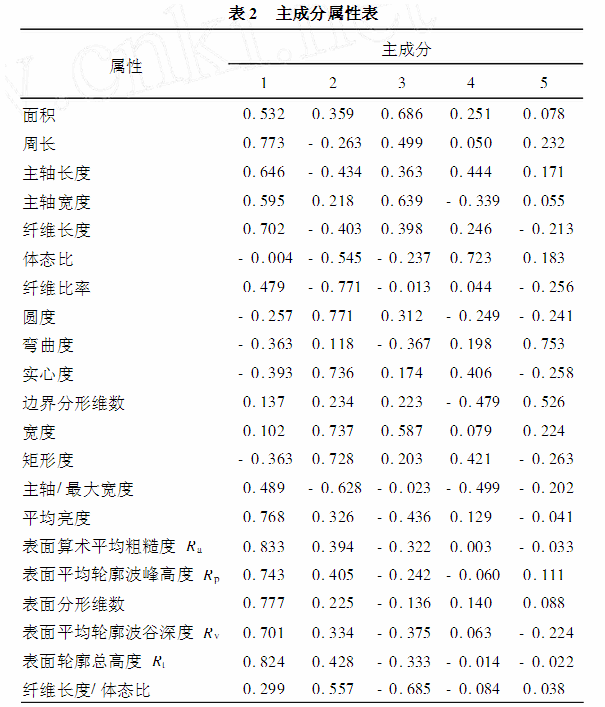
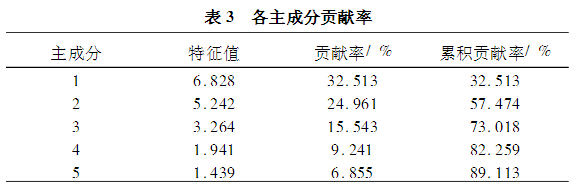
1)属性约简 利用粗糙集理论进行属性约简,在约简前首先选用等距离离散化方法进行离散化处理,然后采用动态约简法对离散化后的滑动轴承磨损试验数据进行约简。采用粗糙集理论约简的目的是寻找属性集合,在此,选用2个约简集合,一个是Z简约简核,为21个属性中的5个{圆度、实心度、纤维长度、宽度、表面平均轮廓波峰高度Rp},另一个是具有不可辨识关系的约简集合,该集合有9个属性分别为{圆度、实心度、纤维长度、主轴/Z大宽度、宽度、表面平均轮廓波峰高度Rp、矩形度、体态比、弯曲度}。 利用主成分分析进行属性约简,通过对滑动轴承磨损试验数据进行标准化、建立协方差矩阵、求解特征根等,得到标准化后的无量纲的磨损形式数据表的主成分如表2所示,通过贡献率计算可知前5个主成分的贡献率已超过89%(见表3),也就是可以保证89%的分类信息不会丢,因此将原试验数据表约简至5维。
滑动轴承磨损试验中共获得了4种磨损状态下的65组数据,随机选取其中的49组作为SVM的学习训练样本,其余16组作为测试样本,并保证每种磨损形式下都有训练和测试样本。为了获取2种约简模式下比较客观的磨损映射关系的结果,随机挑选5次以形成5次训练和测试样本,并以5次测试结果的平均值作为Z终的测试结果。便于结果的对比分析,并做了3个大类(共7组)的磨损映射关系识别训练和测试,第1类包括使用粗糙集约简前的离散化数据A、用粗糙集约简得到的只含有5个属性的Z简核B及粗糙集理论约简得到的含有9个属性的C;第2类是使用主元分析法得到的降维后的5维数据D;第3类是采用原始数据即没有离散化的监测数据进行训练和测试,具体为包括所有属性的E、使用粗糙集约简后含有5个属性的F以及使用粗糙集约简后含有9个属性的G,其测试结果及耗费的时间见表4。

3 结语
滑动轴承典型磨损过程中产生的磨粒信息和磨损表面的对应关系研究对其故障诊断具有重要的意义。随着仪器设备的发展,磨损监测过程中可以获得的数据越来越多,但这些数据之间存在冗余及关联,对于利用机器学习来进行自动识别不利。针对这一问题,通过比较分析粗糙集理论和主元分析2种方法,找出了适合滑动轴承磨粒信息和磨损表面映射关系的识别方法,即首先运用粗糙集理论对监测数据进行约简得到Z简核,然后将其作为SVM的输入并进行训练,便可获得较满意的滑动轴承磨损表面和磨粒信息映射关系识别器。
参考文献
[1]周仲荣.摩擦学发展前沿/学科发展战略研究报告[M].北京:科学出版社,2006.
[2]杨其明,严新平,贺石中.油液监测分析现场实用技术[M].北京:机械工业出版社,2006.
[3]袁成清,严新平,彭中笑.磨粒三维表面形貌获取技术的研究[J].武汉理工大学学报,2005,27(7):88-90.
[4]谢 川,倪世宏.基于粗糙集理论的飞行数据模式特征提取[J].计算机工程,2005,31(6):169-171.
[5]赵广社,张希仁.基于主成分分析的支持向量机分类方法研究[J].计算机工程与应用,2004,40(3):37-38.
[6]边肇祺,张学工.模式识别[M].北京:清华大学出版社,2000.
[7]张国云,章 兢,向文江.滚动轴承技术故障诊断的支持向量机方法研究[J].计算机工程与应用,2005,41(16):227-229.
来源:《武汉理工大学学报》2009年6月